
Lancers(ランサーズ)というサービスに登録されている案件を参考に、実践的なスクレイピングに挑戦してみましょう。今回は “レンタルサーバの空き状況を取得する” という案件を参考にします。
案件の内容を確認(というか、Python の勉強用に調整)
実際に案件を担当する際には、どういった項目を、どの様な形式で出力するのか等をお客様と細かく確認して下さい。今回は勉強しやすいように以下とさせていただきました。
- SPACEMARKET というレンタルスペースを紹介するサービスから情報を取得する
- 対象の地域は「新宿区」「渋谷区」「武蔵野市」のみとする
- 「評価が高い順」で 先頭 3 件のレンタルスペースを対象とする
- 該当が 2 件以下の場合は考慮しない
- 以下の項目を取得し、CSVファイルで出力する
- 地域
- レンタルスペースの会場名
- レンタルスペースのホスト名
- 評価
当日の空き状況※requests では取得できないので対象外- 金額(時間毎)
“当日の空き状況” がブラウザで見ると表示されており、一見、取得できそうな情報です。しかし、実態はページを表示した後、JavaScript の “Ajax” という技術を使って “非同期” で取得した情報で上書きしてます。こういった情報はブラウザの動きを模倣するライブラリを使わないと取得できません。今回はそこまで対応すると範囲が広くなりすぎてしまうので要件から省きました。
ログ出力の準備
スクレイピング中の進捗が分かるようにしたいので、こちらを参考にログ出力の準備もしておいて下さい。
Python で仕事 実務で使う ログ準備編
ただし、当作業用にログ出力を分けたいので設定ファイル「logging.conf」を若干、修正します。
具体的には loggers に「sorkScraping」を、handlers に「fileScrapingHandler」を、更にそれに対する設定をファイル下部に追加します。
[loggers]
keys=root,sampleWork,workScraping
[handlers]
keys=consoleHandler,fileHandler,fileScrapingHandler
[formatters]
keys=sampleWorkFormatter
[logger_root]
level=DEBUG
handlers=consoleHandler
[logger_sampleWork]
level=DEBUG
handlers=consoleHandler,fileHandler
qualname=sampleWork
propagate=0
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=sampleWorkFormatter
args=(sys.stdout,)
[handler_fileHandler]
class=FileHandler
level=DEBUG
formatter=sampleWorkFormatter
args=(__import__("datetime").datetime.now().strftime('Python_de_work/logs/sampleworks_%%Y-%%m-%%d.log'), 'a+')
[formatter_sampleWorkFormatter]
; If you use "decologging" module, you can also use these placeholders, too.
; - real_filename: e.g., /workspace/Python_de_work/work_20210805.py
; - real_funcname: e.g., main
; - real_lineno: e.g., 30
format=[%(asctime)s] - %(name)s - %(levelname)-8s - %(message)s
datefmt=
[logger_workScraping]
level=DEBUG
handlers=consoleHandler,fileScrapingHandler
qualname=workScraping
propagate=0
[handler_fileScrapingHandler]
class=FileHandler
level=DEBUG
formatter=sampleWorkFormatter
args=(__import__("datetime").datetime.now().strftime('Python_de_work/logs/work_scraping_%%Y-%%m-%%d.log'), 'a+')
作成するプログラムを、ちょっとだけ親切なものに…
また、今回のプログラムではいくつかの引数を使用します。そのため、引数の使い方をユーザーに教えるために「argparse」というモジュールを使用しました。こちらのモジュールについては以下の記事を参照下さい。
argparse — コマンドラインオプション、引数、サブコマンドのパーサー
Argparse チュートリアル
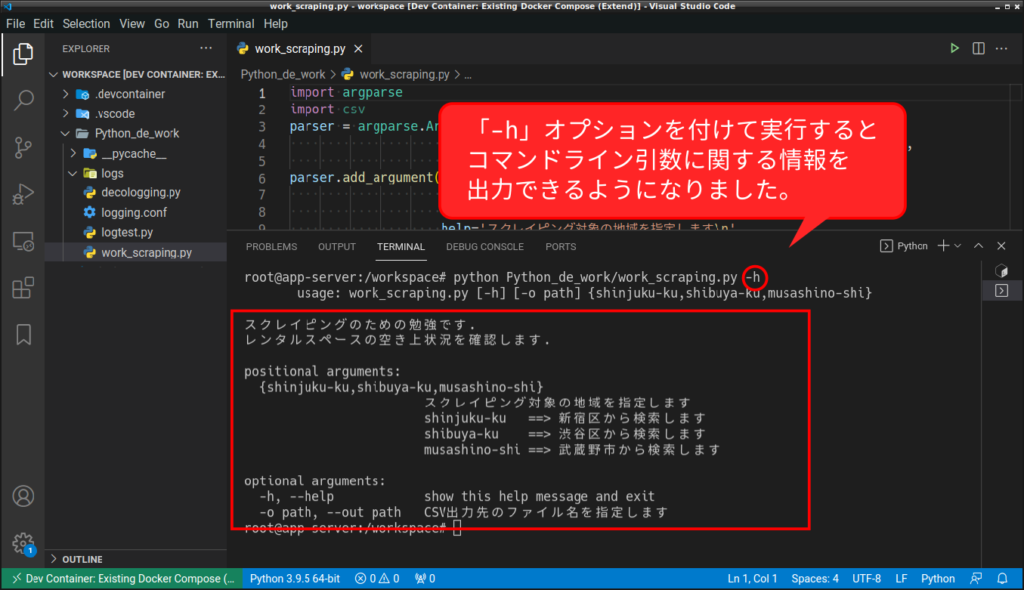
まずは、ここまでで一度「argparse」と、「decologging」が正しく動いているか確認してみましょう。
import argparse
import csv
import datetime
import time
parser = argparse.ArgumentParser(description='スクレイピングのための勉強です.\n'
'レンタルスペースの空き上状況を確認します.',
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('city_name',
choices=['shinjuku-ku', 'shibuya-ku', 'musashino-shi'],
default='shinjuku-ku',
help='スクレイピング対象の地域を指定します\n'
'shinjuku-ku ==> 新宿区から検索します\n'
'shibuya-ku ==> 渋谷区から検索します\n'
'musashino-shi ==> 武蔵野市から検索します')
parser.add_argument('-o', '--out',
metavar='path',
type=argparse.FileType('w', encoding='utf-8'),
help='CSV出力先のファイル名を指定します')
args = parser.parse_args()
from bs4 import BeautifulSoup
import requests
import decologging
logger = decologging.get_logger('workScraping')
@decologging.log(logger)
def main(city_name, csv_filepath):
"""レンタルスペースの空き状況をスクレイピングする.
Args:
city_name (str): スクレイピング対象のエリア
csv_filepath (_io.textIOWrapper): CSV ファイルの出力先
"""
logger.debug(f'(args) city_name: {city_name}, csv_filepath: {csv_filepath} {type(csv_filepath)}')
# 該当ページにリクエスト
# パース(解析)
# 出力 ※もし「--out」引数が指定されている場合は、ファイル出力
if __name__ == '__main__':
main(args.city_name, args.out)
robots.txt を確認する
robots.txt で禁止されているアクセスなどがないかを確認します。以下は 2021年8月13日時点の情報です。(robots.txt はサイトの TOP に配置されてるのでブラウザを使って取得)
User-agent: * Disallow: /i/* Disallow: /*/*/calendar Disallow: /users/* Disallow: /owners/* Disallow: /itineraries/* Disallow: /spaces/*/rooms/*/reservations #Disallow: /owners/*/tokushoho #Disallow: /about/terms #Disallow: /about/privacy #Disallow: /about/tokushoho #Disallow: /about/terms_of_space_use #Disallow: /help User-agent: MJ12bot Disallow: / User-agent: AhrefsBot Disallow: / User-agent: BLEXBot Disallow: / User-agent: bingbot Crawl-delay: 30
今回のスクレイピング対象(詳細は下記)には影響しない内容のようです。ただし前々回の記事(こちら)にも記載したように、連続したリクエストは “攻撃” とみなされるので、リクエストの間隔を 1 秒以上あけるようにしましょう。
スクレイピングの手順を考える
スクレイピング対象の URL を特定する
実際にサイトを利用して、リクエスト(特に URL)に規則がないかを確認します。ここは地道に行うしかありません。結果、以下のことが分かりました。
- エリアの指定は URL を用いる
https://www.spacemarket.com/search/areas/tokyo/cities/{ここに指定する}- 新宿区は「shinjuku-ku」、渋谷区は「shibuya-ku」、武蔵野市は「musashino-shi」
- 「評価が高い順」はクエリパラメータ「sortOrder=DESC」と「sortType=REPUTATION_SCORE」で指定する
※「クエリパラメータ」とは URL で「?」より後に続いてパラメータを指定する方式 - クエリパラメータ「priceType=HOURLY」を使用すると、時間毎の使用料金が表示される
- クエリパラメータに「startedAt=2021-08-16」の用に日付を指定すると、その日の情報が表の先頭に表示される。(各レンタルスペースの詳細ページに遷移しても、その情報は保持されることを確認済み)

今回は、このパターンで割り出した URL で対象のレンタするペース一覧を取得し、更にその詳細ページをスクレイピングすることで必要な情報が揃うという二段構えになっています。
※実践的なスクレイピングの練習になるよう、簡単になりすぎないように調整しています
取得したい情報の位置を特定する(CSS セレクタ等)
これも地道に確認してパターンを割り出すしかありません。一番簡単に手がかりを掴むのは Google Chrome 等のモダンブラウザに付属の “開発者ツール” を使用する方法でしょう。開発者ツールを使用した CSS セレクタは、XPath 等の取得については、こちらの記事に簡単に記載してありますので、忘れてしまった場合はご参照下さい。
対象要素の指定・抽出 CSS セレクタ、XPath | Python で仕事 スクレイピング編 〜その1:スクレイピングとは〜
今回は詳細ページへのリンク情報を取得するために当初は CSS セレクタでどうにかしようと思って色々と試したのですが納得行かず、XPath を使った手法に切り替えて、再度、色々と試しました。
でも、よくよく考えたら BeautifulSoup は XPath 非対応なので、やっぱり CSS セレクタで頑張るか!という流れに……。
「あれ、こんなことできるかな?」というのを調べる→確認するの繰り返しです。エンジニア歴 10 年超えてもこんなもんです。
※ちなみに「lxml」というライブラリを使用すれば XPath でも大丈夫なようですが、今回は使用するライブラリを極力少なくしたかったので CSS セレクタで対応します。
メモメモ……
※以下は唯一の正解ではないことをご承知おきください
検索結果 詳細ページへのリンク:'a *[role="heading"]' ※親要素である「a」の href 属性、かつ先頭3個が対象 詳細ページ レンタルスペースの会場名:'h1[itemprop="name"]' レンタルスペースのホスト名:'h3[itemprop="legalName"] a' 評価:'*[class^="ReputationStarWithCount__Score"]' 金額(時間毎):'.space-side__money div > strong' ※親要素「div」内の text()
ここまで準備できたら、あとはプログラムを書いて実行→修正を繰り返していきます。まだ試行錯誤が続きます。
プログラムで実行してみる
調査した情報をプログラムに反映していく作業です。でも一気に沢山のプログラムを書いてしまうと、修正箇所も多くなりますので、少しずつ確実に動く箇所を増やしていきます。
一覧から詳細ページへのリンクを取得するところまで
import argparse
import csv
import datetime
import time
parser = argparse.ArgumentParser(description='スクレイピングのための勉強です.\n'
'レンタルスペースの空き上状況を確認します.',
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('city_name',
choices=['shinjuku-ku', 'shibuya-ku', 'musashino-shi'],
default='shinjuku-ku',
help='スクレイピング対象の地域を指定します\n'
'shinjuku-ku ==> 新宿区から検索します\n'
'shibuya-ku ==> 渋谷区から検索します\n'
'musashino-shi ==> 武蔵野市から検索します')
parser.add_argument('-o', '--out',
metavar='path',
type=argparse.FileType('w', encoding='utf-8'),
help='CSV出力先のファイル名を指定します')
args = parser.parse_args()
from bs4 import BeautifulSoup
import requests
import decologging
logger = decologging.get_logger('workScraping')
@decologging.log(logger)
def main(city_name, csv_filepath):
"""レンタルスペースの空き状況をスクレイピングする.
Args:
city_name (str): スクレイピング対象のエリア
csv_filepath (_io.textIOWrapper): CSV ファイルの出力先
"""
logger.debug(f'(args) city_name: {city_name}, csv_filepath: {csv_filepath} {type(csv_filepath)}')
# 該当ページにリクエスト
## 検索結果の情報を取得して、各レンタルスペースの詳細ページへのリンク(URL)を取得する
request_url = f'https://www.spacemarket.com/search/areas/tokyo/cities/{city_name}'
payload = {'sortOrder': 'DESC',
'sortType': 'REPUTATION_SCORE',
'priceType': 'HOURLY',
'startedAt': datetime.date.today()}
r_top = requests.get(request_url, payload)
soup_top = BeautifulSoup(r_top.text, 'html.parser')
## 調べた結果を元に対象の要素を取得する ※BeautifulSoup は「:has」疑似クラスを使用できる
links = soup_top.select('a:has(*[role="heading"])')[:3] # 取得した要素の内、先頭 3 個までを抽出
## 取得した要素から各レンタルスペースの詳細ページへのリンク(URL)を抽出
link_count = len(links)
for i, link in enumerate(links, start=1):
logger.debug(f'[{i}/{link_count}] detail_page_url: {link["href"]}')
# パース(解析)
# 出力 ※もし「--out」引数が指定されている場合は、ファイル出力
if __name__ == '__main__':
main(args.city_name, args.out)
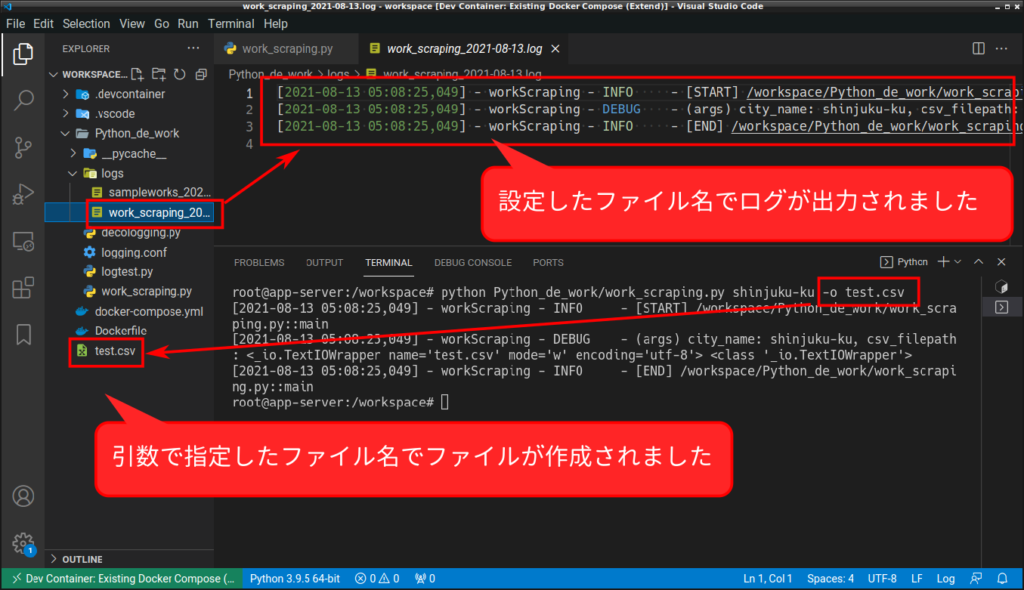
ここまでが正しく動いているか確認します。
python Python_de_work/work_scraping.py shinjuku-ku
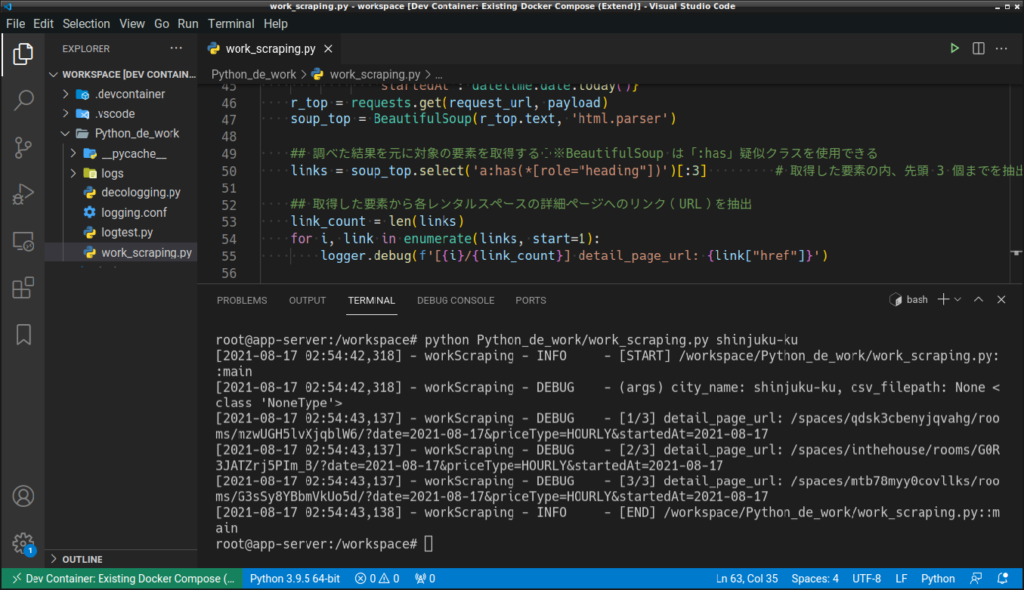
ログから、正しく情報が取得できていることを確認します。
実際にサービスを利用して、内容が一致しているかも随時、確認して下さい。(この記事中では省略します)
[2021-08-17 02:54:42,318] - workScraping - INFO - [START] /workspace/Python_de_work/work_scraping.py::main [2021-08-17 02:54:42,318] - workScraping - DEBUG - (args) city_name: shinjuku-ku, csv_filepath: None <class 'NoneType'> [2021-08-17 02:54:43,137] - workScraping - DEBUG - [1/3] detail_page_url: /spaces/qdsk3cbenyjqvahg/rooms/mzwUGH5lvXjqblW6/?date=2021-08-17&priceType=HOURLY&startedAt=2021-08-17 [2021-08-17 02:54:43,137] - workScraping - DEBUG - [2/3] detail_page_url: /spaces/inthehouse/rooms/G0R3JATZrj5PIm_B/?date=2021-08-17&priceType=HOURLY&startedAt=2021-08-17 [2021-08-17 02:54:43,137] - workScraping - DEBUG - [3/3] detail_page_url: /spaces/mtb78myy0covllks/rooms/G3sSy8YBbmVkUo5d/?date=2021-08-17&priceType=HOURLY&startedAt=2021-08-17 [2021-08-17 02:54:43,138] - workScraping - INFO - [END] /workspace/Python_de_work/work_scraping.py::main
各レンタルスペース詳細ページから必要な情報を取得 ※リクエスト間隔に注意!
詳細ページから必要な情報を取得する段階になります。早速、プログラムを書いていきたいところですが……どんな実装を考えましたか?この辺からプログラマー毎の好みが分かれてくるところかと思います。とりあえず私が考えたパターンを下記いたしますので、ご自身の想定と比べてみて下さい。
- パターン1:54 行目の
forの中で詳細ページを取得し、出力も行う。 - パターン2:54 行目の
forで対象の詳細ページ一覧を作成のみで、別途forを使って詳細ページを取得する。出力は更に別のforを使用する。 - パターン3:「パターン2」の詳細ページ一覧の作成、詳細ページの取得、出力をそれぞれ関数として定義、使用する
一番簡単そうなのは「パターン1」で、逆に大変そうなのは「パターン3」です。
そして私が絶対に選ばないのが「パターン1」で、目指すのは「パターン3」です。
| メリット | デメリット | |
| パターン1 | 単純。 処理時間が短い。 | 処理の塊が大きいため全体像が把握しづらい。 不具合があった場合に、調査する塊も大きくなる。 改良したくなった場合、影響調査する塊も大きくなる。 |
| パターン2 | 処理を小さい塊に分割できるので、不具合があった場合や、改良したい場合に整理しやすい。 | 処理毎に分割ができるが、まだ全体像が把握しづらい。 3回 for ループするので、処理時間が長くなる。 |
| パターン3 | 項目(関数呼出し)と詳細(関数定義)に分割でき、全体像を把握しやすい。 各処理(関数)毎に動作確認ができるので、不具合の調査が容易になる。 | 記載量が多くなる(気がする)。 3回 for ループするので、処理時間が長くなる。 |
結果の比較も兼ねて、パターン2で作成した後、パターン3に移行するようにプログラムしていきましょう。ちなみに、今回は 3 ページだけですが、連続したリクエストの際には必ず間隔を開けるようにしてください。
パターン2での実装
以下が結果になります。このタイミングでライブラリを追加したり、今まで解説したことがないテクニックを使用していますがご了承下さい。”robots.txt” の確認や、ログ出力についても追加・修正をしております。
import argparse
import csv
import datetime
import sys
import time
import urllib.robotparser
parser = argparse.ArgumentParser(description='スクレイピングのための勉強です.\n'
'レンタルスペースの空き上状況を確認します.',
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('city_name',
choices=['shinjuku-ku', 'shibuya-ku', 'musashino-shi'],
default='shinjuku-ku',
help='スクレイピング対象の地域を指定します\n'
'shinjuku-ku ==> 新宿区から検索します\n'
'shibuya-ku ==> 渋谷区から検索します\n'
'musashino-shi ==> 武蔵野市から検索します')
parser.add_argument('-o', '--out',
metavar='path',
type=argparse.FileType('w', encoding='utf-8'),
help='CSV出力先のファイル名を指定します')
args = parser.parse_args()
from bs4 import BeautifulSoup
import requests
import decologging
logger = decologging.get_logger('workScraping')
@decologging.log(logger)
def main(city_name, csv_filepath):
"""レンタルスペースの空き状況をスクレイピングする.
Args:
city_name (str): スクレイピング対象のエリア
csv_filepath (_io.textIOWrapper): CSV ファイルの出力先
"""
logger.debug(f'(args) city_name: {city_name}, csv_filepath: {csv_filepath} {type(csv_filepath)}')
# robots.txt を解析
logger.debug('"robots.txt" を取得して情報を解析します.')
rp = urllib.robotparser.RobotFileParser()
rp.set_url("https://www.spacemarket.com/robots.txt")
rp.read()
delay = rp.crawl_delay("*")
if not delay:
delay = 1
# 該当ページにリクエスト
## 検索結果の情報を取得して、各レンタルスペースの詳細ページへのリンク(URL)を取得する
request_url = f'https://www.spacemarket.com/search/areas/tokyo/cities/{city_name}'
## アクセスしていい URL かどうか確認する
logger.debug(f'検索結果の一覧ページにアクセスして情報を収集します. URL: {request_url}')
if not rp.can_fetch('*', request_url):
logger.warning('このページは "robots.txt" によってアクセスが禁止されています.')
exit('The page is disallow to crawling by the "robots.txt".')
payload = {'sortOrder': 'DESC',
'sortType': 'REPUTATION_SCORE',
'priceType': 'HOURLY',
'startedAt': datetime.date.today()}
r_top = requests.get(request_url, payload)
soup_top = BeautifulSoup(r_top.text, 'html.parser')
## 調べた結果を元に対象の要素を取得する ※BeautifulSoup は「:has」疑似クラスを使用できる
links = soup_top.select('a:has(*[role="heading"])')[:3] # 取得した要素の内、先頭 3 個までを抽出
## 取得した要素から各レンタルスペースの詳細ページへのリンク(URL)を抽出
link_count = len(links)
detail_page_urls = []
for i, link in enumerate(links, start=1):
logger.debug(f'[{i}/{link_count}] 詳細ページのURLを抽出. URL: {link["href"]}')
detail_page_urls.append(f'https://www.spacemarket.com{link["href"]}')
# パース(解析)
scraping_results = []
for i, link in enumerate(detail_page_urls, start=1):
## アクセスしていい URL かどうか確認する
logger.debug(f'[{i}/{link_count}] 詳細ページにアクセスして情報を抽出します. URL: {link}')
if not rp.can_fetch('*', link):
logger.warning('このページは "robots.txt" によってアクセスが禁止されています.')
continue
## 詳細ページの情報を取得する
r = requests.get(link)
soup = BeautifulSoup(r.text, 'html.parser')
## 取得したページから必要な情報を抽出する
scraping_result = {
'会場名': soup.select('h1[itemprop="name"]')[0].text,
'ホスト名': soup.select('h3[itemprop="legalName"] a')[0].text,
'評価': soup.select('*[class^="ReputationStarWithCount__Score"]')[0].text,
'金額(時間毎)最安': soup.select('.space-side__money div strong')[0].text,
'金額(時間毎)最高': soup.select('.space-side__money div strong')[1].text,
}
logger.debug('抽出成功...')
logger.debug(scraping_result)
scraping_results.append(scraping_result)
## 間隔を開ける
time.sleep(delay)
# 出力 ※もし「--out」引数が指定されている場合は、ファイル出力
result_count = len(scraping_results)
logger.debug('結果をファイルまたは、コンソールに出力します')
sys.stdout.close = lambda: None
with (csv_filepath if csv_filepath else sys.stdout) as f:
writer = csv.DictWriter(f,
quotechar='"',
quoting=csv.QUOTE_ALL,
fieldnames=list(scraping_results[0].keys()))
writer.writeheader()
for i, r in enumerate(scraping_results, start=1):
logger.debug(f'[{i}/{result_count}] 出力...')
writer.writerow(scraping_results[0])
if __name__ == '__main__':
main(args.city_name, args.out)
パターン3 に組み替える
ここまで来たら後少しです!ここから先の作業のように既にあるプログラムを、同じ動作を保ったまま書き換えることを “リファクタリング” と言います。「関数に切り出すだけでしょ?」というと、今回はそれだけなのですが……これが実に奥が深い作業になります。試しに Amazon で「リファクタリング」を検索してみて下さい。”リファクタリング” に関する専用の本が、何冊も出版されているんです!
Amazon.co.jp : リファクタアリング ※ 2021年8月17日時点で 92 件の結果
import argparse
import csv
import datetime
import sys
import time
import urllib.robotparser
parser = argparse.ArgumentParser(description='スクレイピングのための勉強です.\n'
'レンタルスペースの空き上状況を確認します.',
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('city_name',
choices=['shinjuku-ku', 'shibuya-ku', 'musashino-shi'],
default='shinjuku-ku',
help='スクレイピング対象の地域を指定します\n'
'shinjuku-ku ==> 新宿区から検索します\n'
'shibuya-ku ==> 渋谷区から検索します\n'
'musashino-shi ==> 武蔵野市から検索します')
parser.add_argument('-o', '--out',
metavar='path',
type=argparse.FileType('w', encoding='utf-8'),
help='CSV出力先のファイル名を指定します')
args = parser.parse_args()
from bs4 import BeautifulSoup
import requests
import decologging
logger = decologging.get_logger('workScraping')
@decologging.log(logger)
def main(city_name, csv_filepath):
"""レンタルスペースの空き状況をスクレイピングする.
Args:
city_name (str): スクレイピング対象のエリア
csv_filepath (_io.textIOWrapper): CSV ファイルの出力先
"""
logger.debug(f'(args) city_name: {city_name}, csv_filepath: {csv_filepath} {type(csv_filepath)}')
# robots.txt を解析
logger.debug('"robots.txt" を取得して情報を解析します.')
rp = urllib.robotparser.RobotFileParser()
rp.set_url("https://www.spacemarket.com/robots.txt")
rp.read()
# 該当ページにリクエスト
detail_page_urls = get_detail_urls(city_name, rp)
# パース(解析)
scraping_results = get_scraping_results(detail_page_urls, rp)
# 出力 ※もし「--out」引数が指定されている場合は、ファイル出力
output_result_to(scraping_results, csv_filepath)
@decologging.log(logger)
def get_detail_urls(city_name, rp):
"""検索結果の情報を取得して、各レンタルスペースの詳細ページへのリンク(URL)を取得する
Args:
city_name (str): スクレイピング対象のエリア
rp (urllib.robotparser.RobotFileParser): "robots.txt" 解析結果
Returns
list: 各レンタルスペースの詳細ページのURL
"""
## 検索結果の情報を取得して、各レンタルスペースの詳細ページへのリンク(URL)を取得する
request_url = f'https://www.spacemarket.com/search/areas/tokyo/cities/{city_name}'
## アクセスしていい URL かどうか確認する
logger.debug(f'検索結果の一覧ページにアクセスして情報を収集します. URL: {request_url}')
if not rp.can_fetch('*', request_url):
logger.warning('このページは "robots.txt" によってアクセスが禁止されています.')
exit('The page is disallow to crawling by the "robots.txt".')
payload = {'sortOrder': 'DESC',
'sortType': 'REPUTATION_SCORE',
'priceType': 'HOURLY',
'startedAt': datetime.date.today()}
r_top = requests.get(request_url, payload)
soup_top = BeautifulSoup(r_top.text, 'html.parser')
## 調べた結果を元に対象の要素を取得する ※BeautifulSoup は「:has」疑似クラスを使用できる
links = soup_top.select('a:has(*[role="heading"])')[:3] # 取得した要素の内、先頭 3 個までを抽出
## 取得した要素から各レンタルスペースの詳細ページへのリンク(URL)を抽出
link_count = len(links)
detail_page_urls = []
for i, link in enumerate(links, start=1):
logger.debug(f'[{i}/{link_count}] 詳細ページのURLを抽出. URL: {link["href"]}')
detail_page_urls.append(f'https://www.spacemarket.com{link["href"]}')
return detail_page_urls
@decologging.log(logger)
def get_scraping_results(detail_page_urls, rp):
"""検索結果の情報を取得して、各レンタルスペースの詳細ページへのリンク(URL)を取得する
Args:
detail_page_urls (list): 各レンタルスペースの詳細ページのURL
rp (urllib.robotparser.RobotFileParser): "robots.txt" 解析結果
Returns
list: 詳細ページから抽出した情報. 次のキーを含むdict型のリスト: [会場名],[ホスト名],[評価],[金額(時間毎)最安],[金額(時間毎)最高]
"""
delay = rp.crawl_delay("*")
if not delay:
delay = 1
link_count = len(detail_page_urls)
scraping_results = []
for i, link in enumerate(detail_page_urls, start=1):
## アクセスしていい URL かどうか確認する
logger.debug(f'[{i}/{link_count}] 詳細ページにアクセスして情報を抽出します. URL: {link}')
if not rp.can_fetch('*', link):
logger.warning('このページは "robots.txt" によってアクセスが禁止されています.')
continue
## 詳細ページの情報を取得する
r = requests.get(link)
soup = BeautifulSoup(r.text, 'html.parser')
## 取得したページから必要な情報を抽出する
scraping_result = {
'会場名': soup.select('h1[itemprop="name"]')[0].text,
'ホスト名': soup.select('h3[itemprop="legalName"] a')[0].text,
'評価': soup.select('*[class^="ReputationStarWithCount__Score"]')[0].text,
'金額(時間毎)最安': soup.select('.space-side__money div strong')[0].text,
'金額(時間毎)最高': soup.select('.space-side__money div strong')[1].text,
}
logger.debug('抽出成功...')
logger.debug(scraping_result)
scraping_results.append(scraping_result)
## 間隔を開ける
time.sleep(delay)
return scraping_results
@decologging.log(logger)
def output_result_to(scraping_results, csv_filepath):
"""詳細ページから抽出した情報(scraping_results)を、csv_filepath を指定している場合はファイルに、
指定していない場合はコンソールに出力する
Args:
scraping_results (list): 詳細ページから抽出した情報.
csv_filepath (_io.textIOWrapper): CSV ファイルの出力先
"""
result_count = len(scraping_results)
logger.debug('結果をファイルまたは、コンソールに出力します')
sys.stdout.close = lambda: None
with (csv_filepath if csv_filepath else sys.stdout) as f:
writer = csv.DictWriter(f,
quotechar='"',
quoting=csv.QUOTE_ALL,
fieldnames=list(scraping_results[0].keys()))
writer.writeheader()
for i, r in enumerate(scraping_results, start=1):
logger.debug(f'[{i}/{result_count}] 出力...')
writer.writerow(r)
if __name__ == '__main__':
main(args.city_name, args.out)
プログラム全体としては長くなってしまいましたが main() 内はかなりスッキリしました。
コメントで書いていたよりも多くの情報をより自然な形で記載することもできましたし、修正や調査も関数単位で切り分けてできます。for を 3 回使うことや、プログラムが長くなるよりも、ずっと大きなメリットを獲得できたのではないでしょうか。
最後に、実際に動かして結果を確認してみましょう。
python Python_de_work/work_scraping.py shinjuku-ku --out test.csv
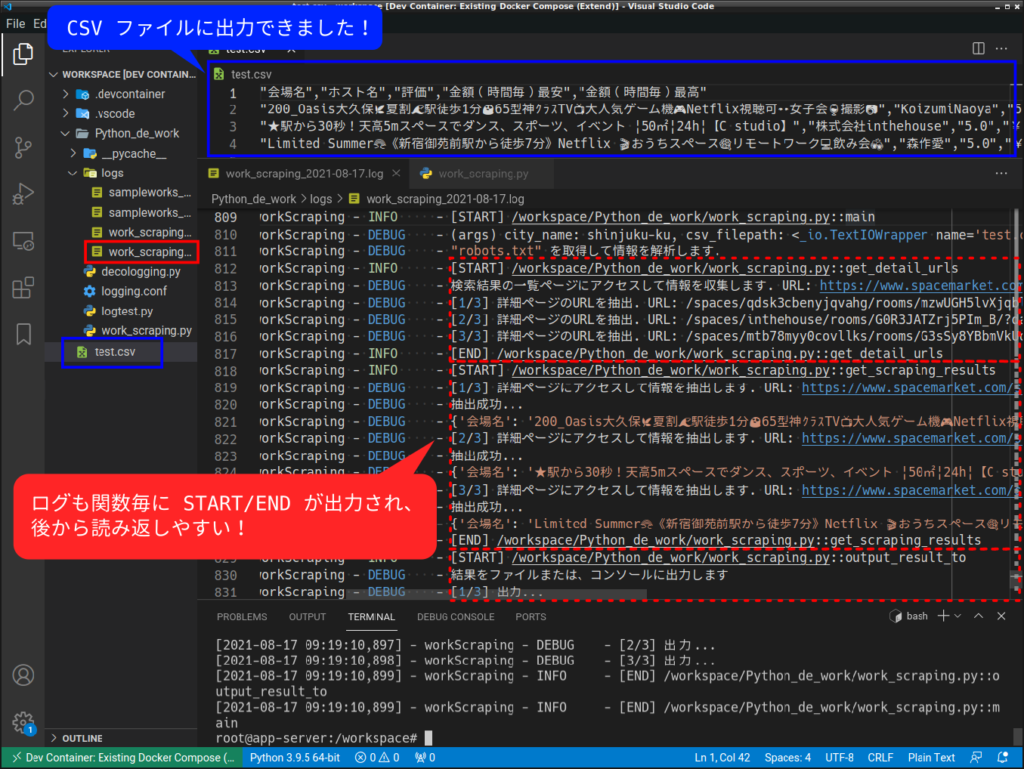
以上で、スクレイピングに関するシリーズは完了となります。最後は長くなってしまった上に、肝心の “空き状況を調べる” というのはできませんでしたが、Python を使ったスクレイピングの概要は掴めたと思います。
今回のシリーズが何かのお役に立てれば幸いです。ありがとうございました。

コメント