
弊社(アパルーサ・ユニバース株式会社)では課題管理に Backlog を使用することがあります。(他にも Redmine や Github Issue など案件により様々ですが)
その Backlog には API が準備されていて、ドキュメントもしっかり準備されているので簡単に使うことができます。今回はこの API を使って課題の一覧を取得するためのツールを Python で作ってみましょう。
Backlog API の詳細については公式ドキュメントをご参照下さい。

Backlog API を利用するには以下のパターンがあるようです。
ライブラリを使用してもいいのですが、今回はそこまで難しいことをしたいわけじゃないので、準備が簡単な “API Key を使用する” 方法を採用したいと思います。今回は折角なので「curl」というコマンドの使い方も合わせて勉強しましょう!
- Backlog API を利用するための準備として API Key を発行する
- 対象のプロジェクトの 絞るために “プロジェクトID” を取得する ※ここで
curlを使用する - 対象の課題一覧を取得して CSV に出力する ※ここで Python を使用する
Backlog API を利用するための準備として API Key を発行する
Backlog API を使用するための API Key の取得はとても簡単です。ログイン後、”個人設定” の画面から API Key を発行します。
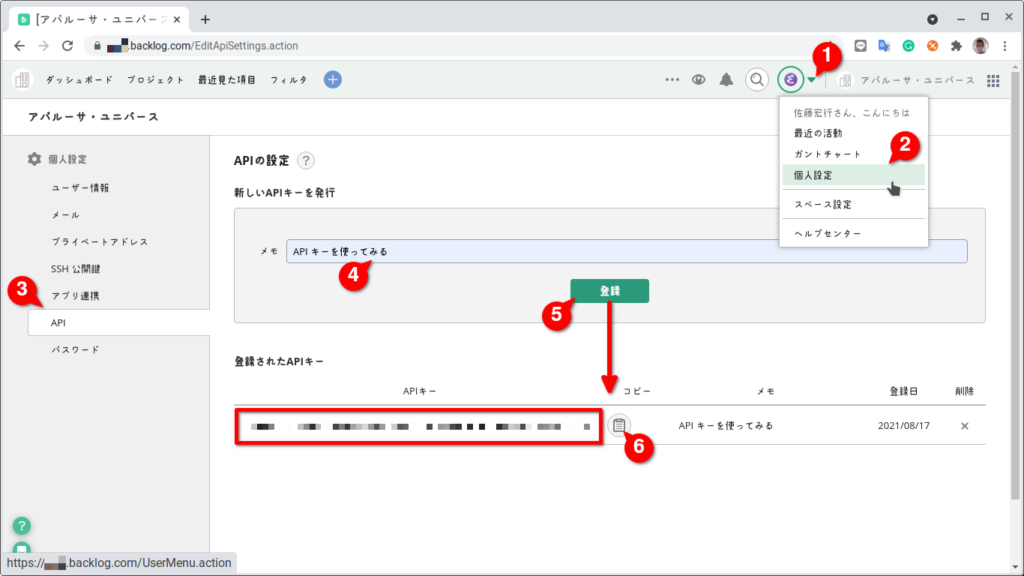
対象のプロジェクトの 絞るために “プロジェクトID” を取得する
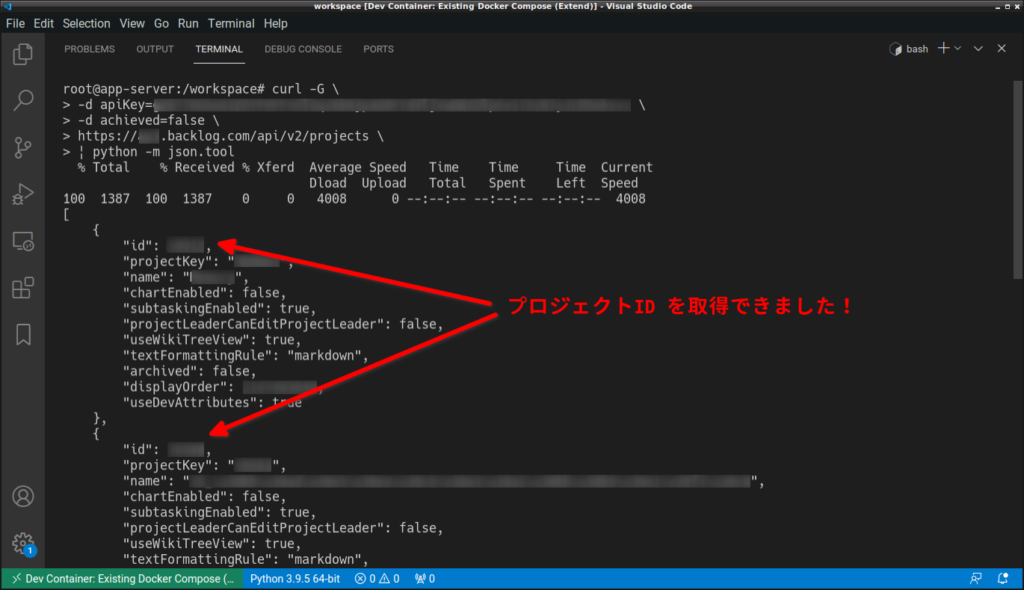
プロジェクト一覧を取得する API については、こちらに記載されています。「curl」コマンドを使ってプロジェクト一覧の情報を取得してみましょう。
※ curl の詳細はこちら。本投稿下部にも少し情報を載せておきます
プロジェクト一覧の取得 | Backlog Developer API
- URL は「https://{スペース毎に異なる}.backlog.com/api/v2/projects」
※{スペース毎に異なる}.backlog.jp の場合もあるようです - HTTP Request 時は GET で取得する
- API Key は「apiKey=xxxxxxxxxxx」の形式で指定する
- パラメータ(archived、all)は省略可能。勉強のために「acheived=false」のみ使用する
curl コマンドでは以下のようになります。拍子抜けするくらい簡単ですね。
curl -G \ -d apiKey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ -d achieved=false \ https://xxx.backlog.com/api/v2/projects \ | python -m json.tool
ただし、上記のコマンドだけでは日本語が Unicode で表示されてしまいます。日本語で結果を取得したい場合は、以下のコマンドを使用して下さい。
curl -G \ -d apiKey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \ -d achieved=false \ https://xxx.backlog.com/api/v2/projects \ | python -c ' from sys import stdin; import json; print(json.dumps(json.loads(stdin.readline()), indent=2, ensure_ascii=False)) '
使用したパラメータ等はそれぞれ以下の用途です。
- 「-G」 リクエストに GET を使用する
- 「-d」 パラメータを指定する(復数可)
- 「\」 次の行にコマンドが続くことを意味する
- 「|」 取得した結果を次のコマンド(python)に渡す
- 「python -m json.tool」 JSON 文字列をキレイに表示するためのおまじない
- 「python -c」 ファイルではなく文字列で Python プログラムを実行するおまじない
対象の課題一覧を取得して CSV に出力する
ようやく Python の出番です!ここまでで取得した API Key と プロジェクトID を使用して、課題の一覧を取得しましょう。課題一覧取得の API について以下を参照下さい。
課題一覧の取得 | Backlog Developer API
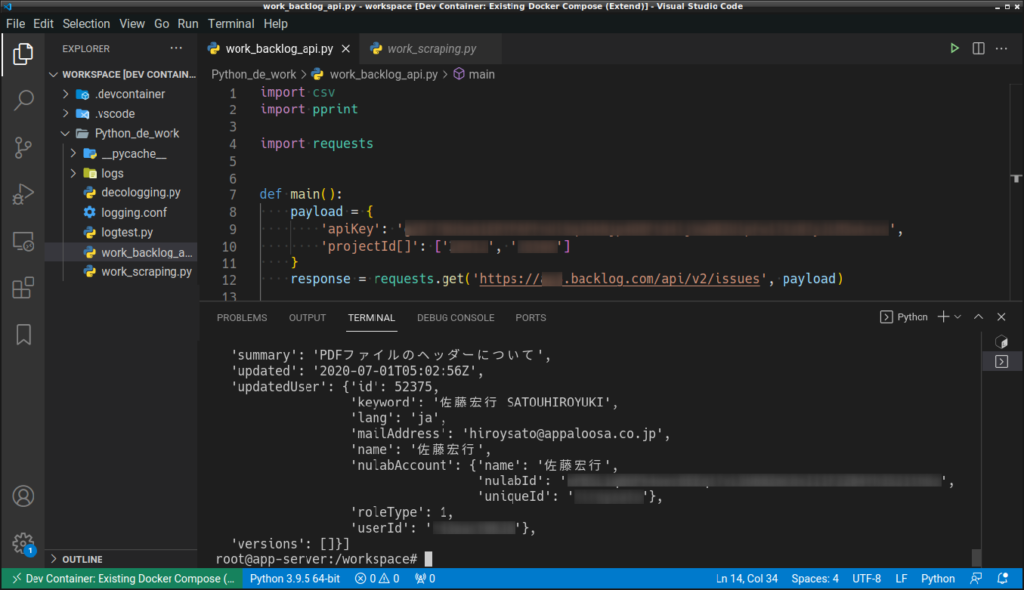
まずは想定しているライブラリやパラメータで情報を取得できるかどうか、簡単な確認だけ先に済ませましょう。
import csv
import pprint
import requests # サードパーティ製のライブラリなので pip コマンドでインストールしましょう
def main():
payload = {
'apiKey': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'projectId[]': ['xxxxx', 'xxxxx']
}
response = requests.get('https://xxxxx.backlog.com/api/v2/issues', payload)
pprint.pprint(response.json()) # pprint は対象を整形して出力してくれる便利なライブラリ
if __name__ == '__main__':
main()
あっさりできましたね。次はもう少し条件を増やしたり、必要な情報のみを抽出して、ファイルやコンソールに出力できるように修正しましょう。慣れていないうちは、細かく確認しながら進むのがオススメです。例えば次のような条件を指定したい場合、それぞれに必要な情報を API から取得する必要があります。その際はまた「curl」コマンドを使用して情報を収集しましょう。
- 担当者が自分の課題だけ取得したい → 認証ユーザー情報の取得
- ステータスが「処理中」「未対応」の課題だけ取得したい → プロジェクトの状態一覧の取得
認証ユーザ情報の取得
各パラメータについては、上記をご確認下さい。
curl -G \
-d apiKey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
https://xxxxxxxx.backlog.com/api/v2/users/myself \
| python -c '
from sys import stdin; import json;
print(json.dumps(json.loads(stdin.readline()), indent=2, ensure_ascii=False))
'
プロジェクトの状態一覧の取得
curl -G \
-d apiKey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx \
https://xxxxxxxx.backlog.com/api/v2/projects/xxxxx/statuses \
| python -c '
from sys import stdin; import json;
print(json.dumps(json.loads(stdin.readline()), indent=2, ensure_ascii=False))
'
この時にどれだけ凝った作りにするか……というのが迷いどころです。スクレイピングの勉強の際はコマンドパラメータを指定できるようにしたりと凝ったことをしました……が、今回はそこまでやらなくてもいいでしょう。
※コマンドパラメータや、ヘルプドキュメントの設定の仕方はこちらの記事を参照下さい

必要な情報が揃ったので、プログラムに反映しましょう。今回は自分が使うツールなので極力シンプルに作っています。
- API Key やプロジェクトID 等「xxxxx」で記載している部分は、実際の値を設定して下さい
- ログは出力していません
- ファイル出力はしていません
import csv
import pprint
import sys
import requests
def main():
"""Backlog に登録されている課題を以下の条件で取得し CSV 形式で出力する
- 対象プロジェクト: 「あいうえおプロジェクト」「かきくけこプロジェクト」
- ステータス: 「未対応」「処理中」
- 担当者: 「佐藤宏行」
- 並び順: 期限日の降順
"""
target_projects = {
xxxxx: 'あいうえお', # xxxxx の部分には、上で取得したプロジェクトIDを設定して下さい
xxxxx: 'かきくけこ', # (同上)
}
target_statuses = [
1, # 未対応
2, # 処理中
]
payload = {
'apiKey': 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'projectId[]': [list(target_projects.keys())], # 対象プロジェクトを指定
'statusId[]': [target_statuses], # ステータス「未対応」「処理中」追加
'assigneeId[]': [xxxxx], # 担当者に私(佐藤宏行)を追加
'sort': 'dueDate', # 並び替えの指定: "期限日"
'order': 'desc', # "降順"
}
issues = requests.get('https://ap3.backlog.com/api/v2/issues', payload)
results = []
for issue in issues.json():
result = {
'プロジェクトID': issue['projectId'],
'プロジェクト名': target_projects[issue['projectId']],
'件名': issue['summary'],
'ステータス': issue['status']['name'],
'期限日': issue['dueDate'] if issue['dueDate'] else '(指定なし)',
}
results.append(result)
sys.stdout.close = lambda: None
with (sys.stdout) as f:
writer = csv.DictWriter(f,
quotechar='"',
quoting=csv.QUOTE_ALL,
fieldnames=list(results[0].keys()))
writer.writeheader()
for i, r in enumerate(results, start=1):
writer.writerow(r)
if __name__ == '__main__':
main()
これでブラウザを開いてログインすることなく課題の一覧が取得できるようになりました。
条件や取得対象等を工夫すれば色々な使い方ができると思います。例えば…
- 今日やる課題一覧を取得するツール
- 当日、完了した課題一覧を取得するツール(日報用に)
- 課題数(バグ数)推移を調査するツール
簡単ではありますが、Web API の使い方も勉強できました。お付き合いいただきありがとうございました。
(おまけ)curl について
Windows 10 に付属している curl は、下記 “大人の事情” によりオリジナルのものとは若干異なるようで注意が必要です。
Windows 10に付属しているのは、cURLの仕様からMicrosoftが作った独自バージョンのようである。というのもMicrosoft社内には、Windowsに「オープンソースソフトウェア」を載せないというルールがあり、こうしたコマンドやAF_UNIX、9pサーバー/クライアントなどは、すべてMicrosoftが仕様を元に自社内でゼロから作ったプログラムであるようだ。実際、Windows 10に付属のcurl.exeと、オープンソース版cURLのWindows公式配布バイナリではバージョン表記などに違いがある。
ASCII.jp : Windows 10で標準で用意されるようになったcurlを使ってみる


コメント