
仕事を探す
Python を仕事や副業に活かしたい!
試しに、Lancers(ランサーズ)というサービスで気軽にできる Python の案件がないか調べてみます。一人で気軽に初められる案件を探すために以下の条件で検索しました。
- キーワード:python
- 除外キーワード:AI システム開発
結果、とても顕著だったのが「Web スクレイピング」に関する案件が多いということです。(2021年8月現在)”Web スクレイピング” とは、Web サイトを巡回して必要な情報を抽出・加工することで、実際の仕事の内容は
- あるECサイトから、商品名△△で検索した結果を取得・一覧化するツールが欲しい
- ある求人サイトにて、募集されている情報を収拾・カテゴライズするツールが欲しい
といったものです。
幸いなことに Python にはスクレイピングを簡単にするためのライブラリがあります。今回は、ランサーズに登録されている案件を題材にしてスクレイピングの練習をしてみましょう。
※案件の内容を参考にしますが、実際の内容からは変更します
前提知識やルール等
最低限の用語は先に覚えておきましょう。そうしないと仕事内容やライブラリの解説を読んでも何も手につかなくなってしまいます。
前提知識
スクレイピングとクロール
“スクレイピング” と似た用語に “クロール” というものがあります。どちらもWeb サイトを巡回しますが、クロールの方は Google 等が行う行為で検索サービスを提供する際に使用します。そのためスクレイピングが始めから狙った情報を取得しようとするのに対し、クロールは探索するように巡回します。
HTML と HTTP
HTMLは「Hyper Text Markup Language」の略で、ホームページを作成する際に利用されている言語になります。”タイトル” や “文章” 以外にも “画像” 等を用いて文章を構成できるようになっています。一方、HTTPは「Hyper Text Transfer Protocol」の略で、HTML情報をインターネットを経由して転送(Transer)する際の規約(Protocol)です。
※補足 「ハイパーテキスト」…文字以外に画像や音声を含む文章、「マークアップ」…”タグ” を用いて構成に意味づけする作業(”タイトル”、”段落” など)
クライアントとサーバ、ブラウザ
クライアントは要求(リクエスト)する側、サーバは応答(レスポンス)する側です。HTMLの場合は、クライアントが「このURLの記事を欲しいです」と要求すると、サーバはHTMLをHTTPに則って返してくれます。ブラウザはクライアントの一種です。Python を使用してスクレイピングする際、ブラウザの代わりにクライアントを担ってくれるモジュールを使用して、サーバに要求(リクエスト)します。
対象要素の指定・抽出 CSS セレクタ、XPath
対象ページの HTML を取得したとして、そこから必要な情報を抽出するためには要素を指定する必要があります。その要素の指定には一般的に「CSS セレクタ」か「XPath」という方法を使用します。以下は私の勝手な印象ですが……
- CSS セレクタ … HTML に特化しているので使いやすい
- XPath … XML 全般に使えて、柔軟。 ※ HTML も XML の仲間
試しにこのページに含まれる画像をそれぞれの方法で指定してみます。これには Google Chrome の開発者ツールを使うのが一番簡単ですので、その使い方も是非、覚えて下さい。「Copy selector」では CSS セレクタ、「Copy XPath」では XPath による要素指定時の文字列を取得することができます。
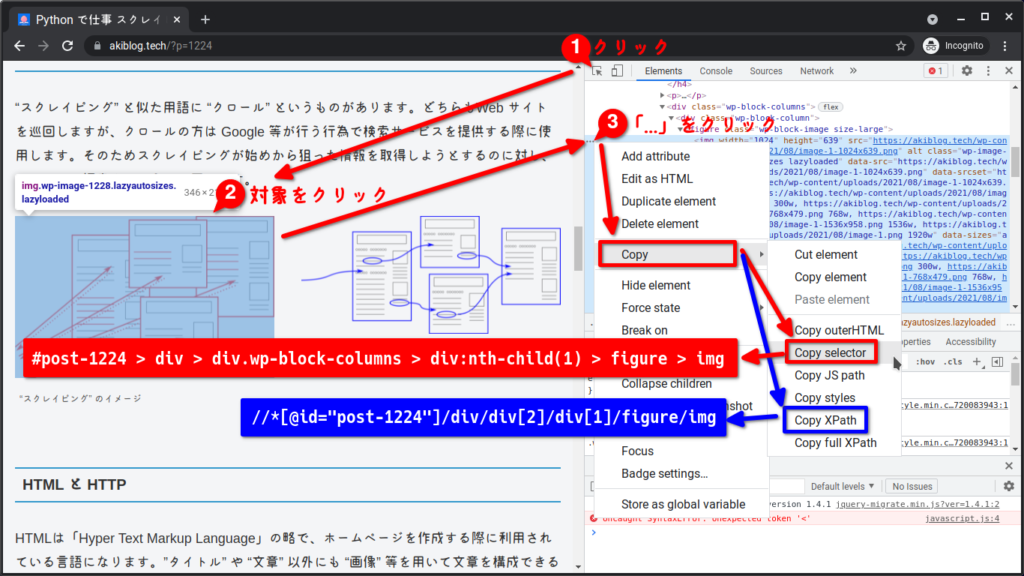
この例だけ見ると、XPath の方が簡潔に思われるかも知れません。しかし、CSS セレクタの方は「#post-1224」や「.wp-block-columns」という風に HTML の id、class 属性を簡潔に指定する書式がありますので、CSS セレクタの方が簡潔になることの方が多いです。
ルール
robots.txt
robots.txt ファイルとは、検索エンジンのクローラに対して、サイトのどの URL にアクセスしてよいかを伝えるものです。
robots.txt の概要とガイド | Google 検索セントラル
…(略)…
robots.txt ファイルは、基本的にはクローラのサイトへのトラフィックを管理するために使用されます
です。このファイルには規格(REP: Robots Exclusion Protocol)外のものも含めて主に以下の項目が記載されます。
- User-agent … 対象となるクローラーの種類
- Disallow … クロールを禁止するパス
- Allow … クロールを許可するパス
- Crawl-delay … クロールする間隔(秒)
- Sitemap … サイトマップXMLのURL
しかし実際のところ、
robots.txt ファイルの指示をサイトに対するクローラの動作に強制適用することはできません。指示に従うかどうかはクローラ次第です。Googlebot などの信頼できるウェブクローラは robots.txt ファイルの指示に従いますが、他のクローラも従うとは限りません。
robots.txt ファイルの制限事項について | robots.txt の概要とガイド | Google 検索セントラル
このプロトコルは全く拘束力がない。
Robots Exclusion Standard – Wikipedia
という代物です。robots.txt を適切に使用するかどうかの判断は個々人に委ねられていますので、良識あるエンジニアとしては是非、従うように心がけたいところです。
Python にはこの robots.txt を解析してくれるライブラリがありますので、スクレイピングする際には利用するとよいでしょう。
urllib.robotparser — robots.txt のためのパーザ
サーバ負荷
連続したリクエスト、相手サーバに多大な負荷をかけることになり、DoS 攻撃と見做される可能性があり、最悪、アクセス禁止に……。サービス提供者への心遣い、また自分自身の身を守るためにも連続したリクエストをする際には十分、注意して下さい。
“Crawl-delay”(クロールする間隔(秒))が規格外となっているため、前述の robots.txt で指定がないこともありますので、そういった場合は、最低でも “1 秒間” 空けるよう心がけましょう。

コメント