
仕事に取り掛かる前に簡単な練習から始めたいと思います。
Python でスクレイピングする際には、以下のモジュールを使うのが一般的なようです。
- Requests … HTTP クライアント。ブラウザの代わりとして使用。Python 標準ライブラリの「urllib.request」を使いやすくしたもの(本家サイト)
- Beautiful Soup … XML、HTML のパーザ(解析する役割を担う)。Wikipedia のページでは “which is useful for web scraping” と紹介されている(本家サイト)
どちらもサードパーティ製のライブラリなので、「pip」コマンドを用いてインストールしましょう。
pip install requests pip install beautifulsoup4
HTTP リクエストについてもう少し勉強
HTML をサーバに要求(リクエスト)する際、そのリクエストの仕方には種類があります。こちらのページにその一覧がまとめられていますので、その中で特に重要なものを抜粋してご紹介いたします。
- GET … 指定したリソース(HTML や、画像、音声データ)をリクエストします。リクエスト時にパラメータを指定したい場合は URL の一部として情報を記載します。スクレイピングで使用するのは、主にこの手法になります。
- POST … 主に新しい情報を登録・更新したい場合に使用します。お問い合わせフォームの情報をサーバに送信する際などに使用します。サーバに情報を送信することを「ポストする」と表現することが多いです。
HTML 中の<submit>タグに関連してサーバに情報を送信する際、ブラウザが勝手に使用します。 - PUT … 登録済みの情報を更新する際に使用します。
- DELETE … 登録済みの情報を削除する際に使用します。
ちなみに本当の決まりというものは、同ページ内の “仕様書” として載っているように RFC(Request for Comments)という形でまとめられております。この資料は素人にはとても読みづらいです。もっと勉強して、厳密な規格を知りたくなった際に利用するといいでしょう。
Requests の使い方
このブログのトップページをリクエストしてみましょう。
import requests
r = requests.get('https://akiblog.tech/')
print(r.text)
<!doctype html>
<html lang="ja"
...(略)...
<a href="https://akiblog.tech/?p=1224" class="entry-card-wrap a-wrap border-element cf" title="Python で仕事 スクレイピング編 〜その1:スクレイピングとは〜">
<article id="post-1224" class="post-1224 entry-card e-card cf post type-post status-publish format-standard has-post-thumbnail hentry category-4-post category-5-post category-6-post tag-python-post tag-38-post">
<figure class="entry-card-thumb card-thumb e-card-thumb">
<img width="320" content/uploads/2020/06/shutters
続いてパラメータを指定(記事IDを指定)してリクエストしてみます。
import requests
payload = {'p': '1224'}
r = requests.get('https://akiblog.tech/', payload)
print(r.text)
# 上記は以下と全く同じ
# r = requests.get('https://akiblog.tech/?p=1224')
# print(r.text)
<!doctype html>
<html lang="ja"
...(略)...
<header class="article-header entry-header">
<h1 class="entry-title" itemprop="headline">
Python で仕事 スクレイピング編 〜その1:スクレイピングとは〜 </h1>
Beautiful Soup の使い方
パース(解析)する対象が必要なので、先程 Requests を使って取得した HTML を使用します。
今回、情報の抽出には CSS セレクタを使用しております。CSS セレクタについては、ここでは細かくご紹介できません……申し訳ありませんがご自身でご確認をお願いいたします。
from bs4 import BeautifulSoup
import requests
payload = {'p': '1224'}
r = requests.get('https://akiblog.tech/', payload)
soup = BeautifulSoup(r.text)
headers = soup.select('h4 span') # CSS セレクタを使用した要素の指定の仕方
for h in headers:
print(h.text)
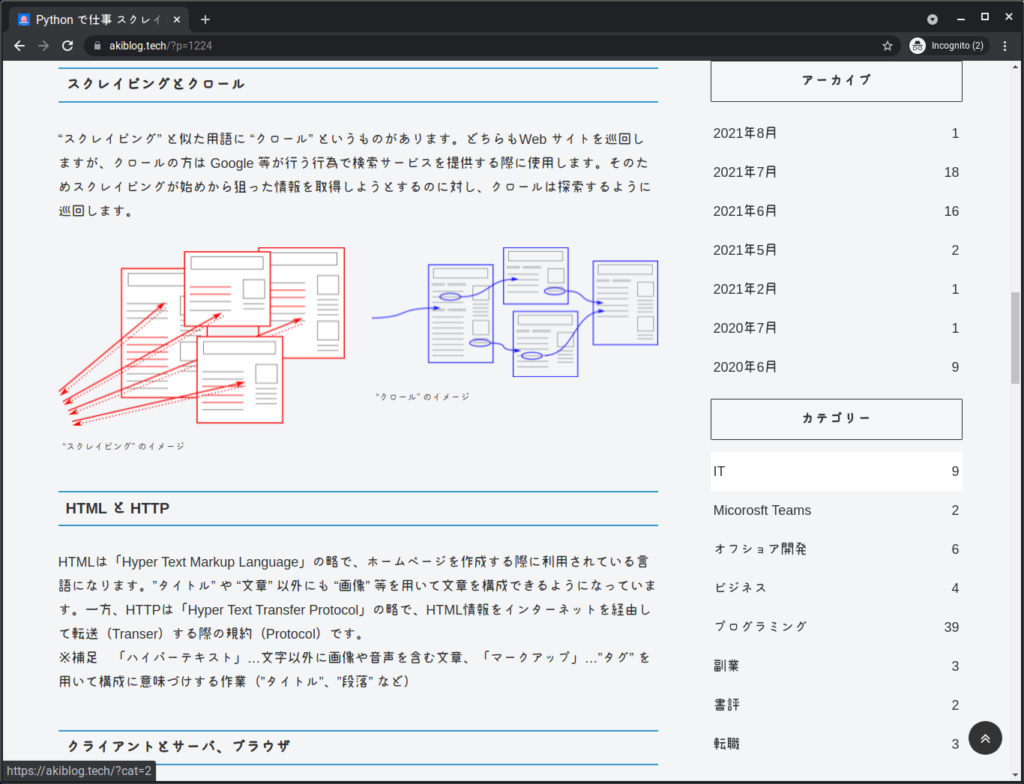
スクレイピングとクロール HTML と HTTP クライアントとサーバ、ブラウザ 対象要素の指定・抽出 CSS セレクタ、XPath robots.txt サーバ負荷
簡単に情報を抽出できました!
次回は案件の内容を参考にして、Python での実装の仕方を勉強したいと思います。


コメント