
前回までで以下の準備、確認が終わりました。
- Twitter API を利用するための開発者アカウントの登録
- Twitter API を利用するための Project と App の登録
- Bearer Token と Twitter API を利用して自分のツイートを取得(
curlコマンド使用)
今回はいよいよ(?)Python を使って取得してみたいと思います。
といっても、Twitter さんがサンプルプログラムを用意してくれているので、そちらを利用してサクッと確認しましょう。
サンプルプログラムが公開されている Github のページへは「Quick start」タブ内から遷移できます。
ページを下にスクロールすると、前提条件(Prerequisites)と言語固有の要件(Language-specific requirements)が記載されています。それぞれ確認しましょう。
前提条件(Prerequisites)
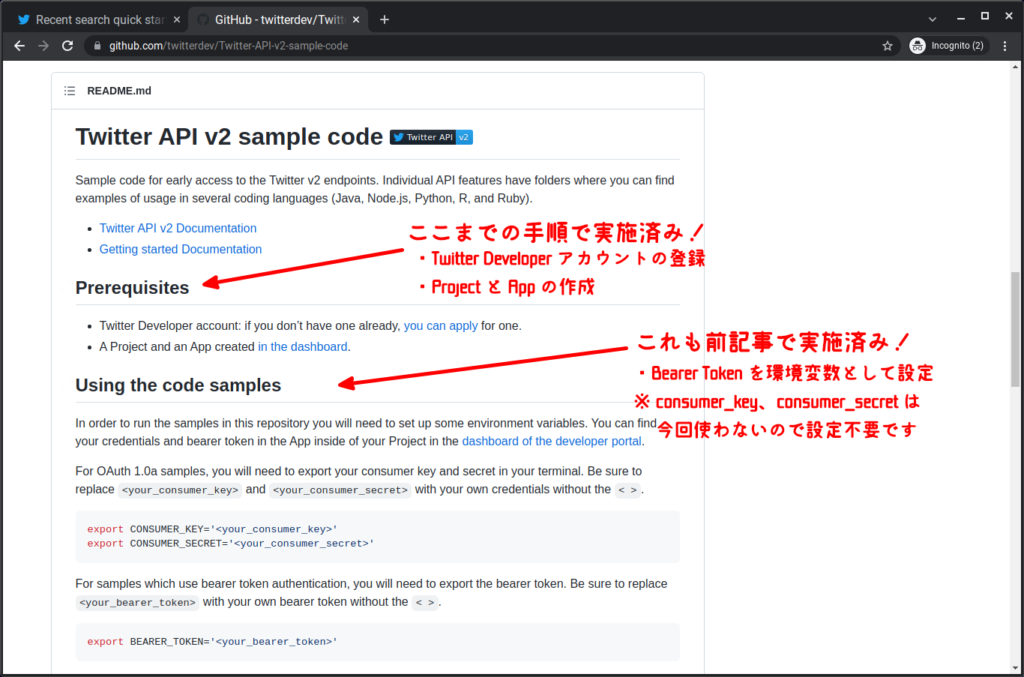
ここまでの手順で既に実施済みになります。
※もし無くしてしまった場合でも、ダッシュボードのページから再発行(Regenerate)できますので安心して下さい
言語固有の要件(Language-specific requirements) ※ Python
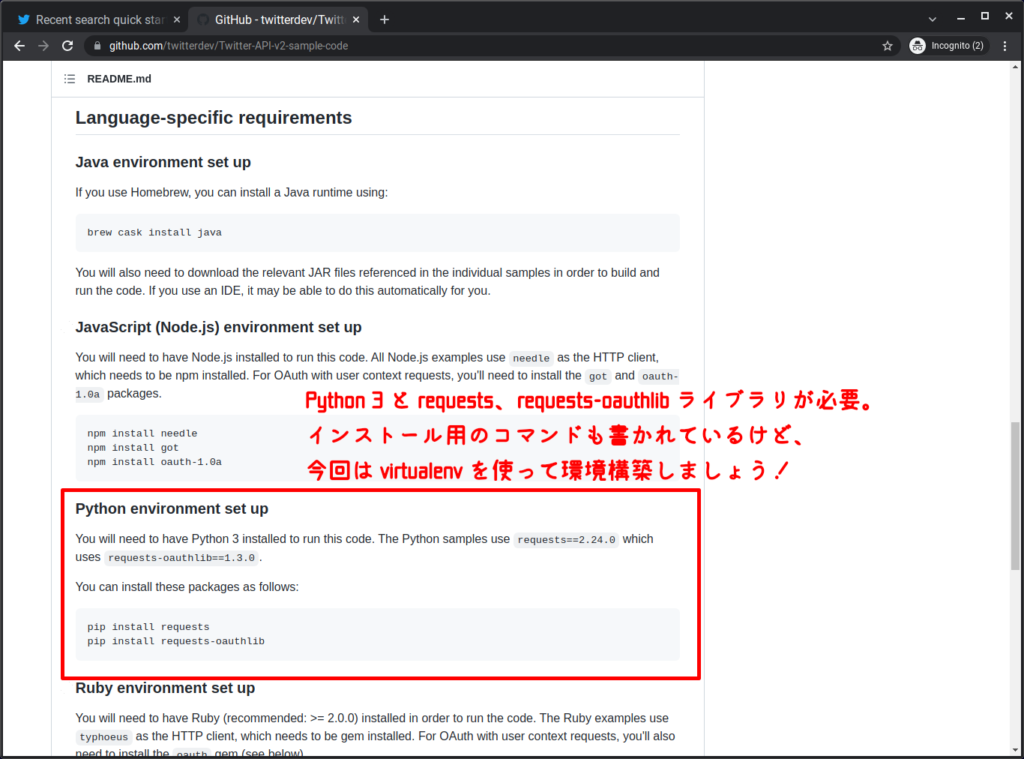
Python3 と 2 個のライブラリが必要とされております。
記載のとおりにインストールしてもよいのですが、折角、前回(YouTube API 編)で virtualenv を勉強しましたので今回も使って開発環境を準備しましょう。詳しくはこちら。

今回の環境名は「Python_de_Twitter_API」にしました。
“requests==2.24.0“、”requests-oauthlib==1.3.0” としているのはバージョンによる違いでサンプルプログラムが動かなくなる事態を避けために、Github の説明とインストールされるライブラリのバージョンを合わせるためのものです。
pip install virtualenv virtualenv Python_de_Twitter_API source Python_de_Twitter_API/bin/activate Python_de_Twitter_API/bin/pip install 'requests==2.24.0' 'requests-oauthlib==1.3.0'
Python でツイートを取得
今回使用するサンプルプログラムまで進みます。
プログラムまで辿り着いたらコピーボタンをクリックします。
前手順で「Python_de_Twitter_API」フォルダが作成されているはずです。その中に新規ファイル「recent_search.py」を作成してサンプルプログラムを貼り付けて下さい。
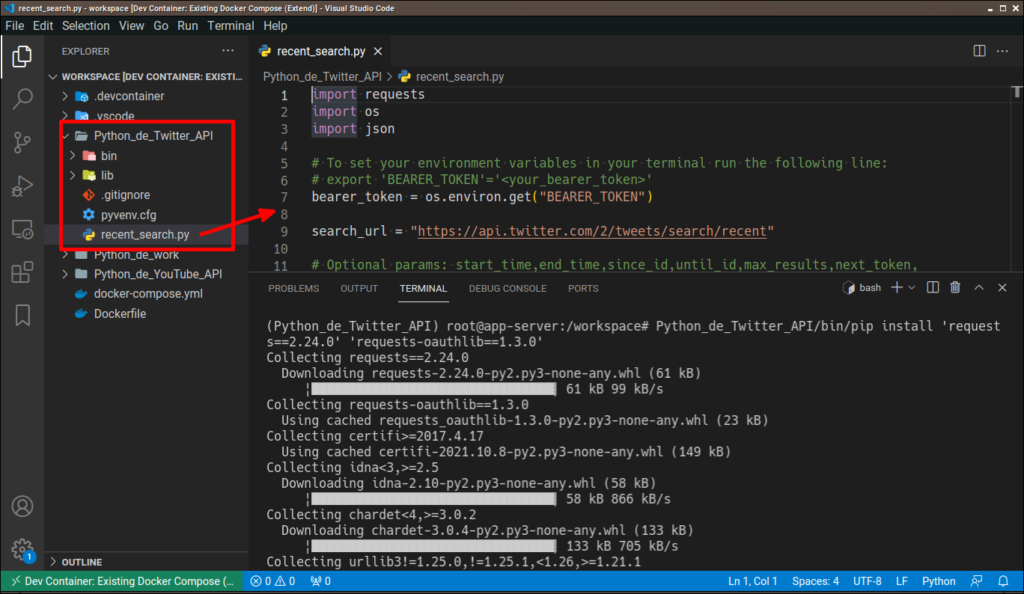
あとは以下のコマンドでプログラムを実行するだけで、(誰のものか分からないけど)ツイートが取得できるはずです。
python Python_de_Twitter_API/recent_search.ph
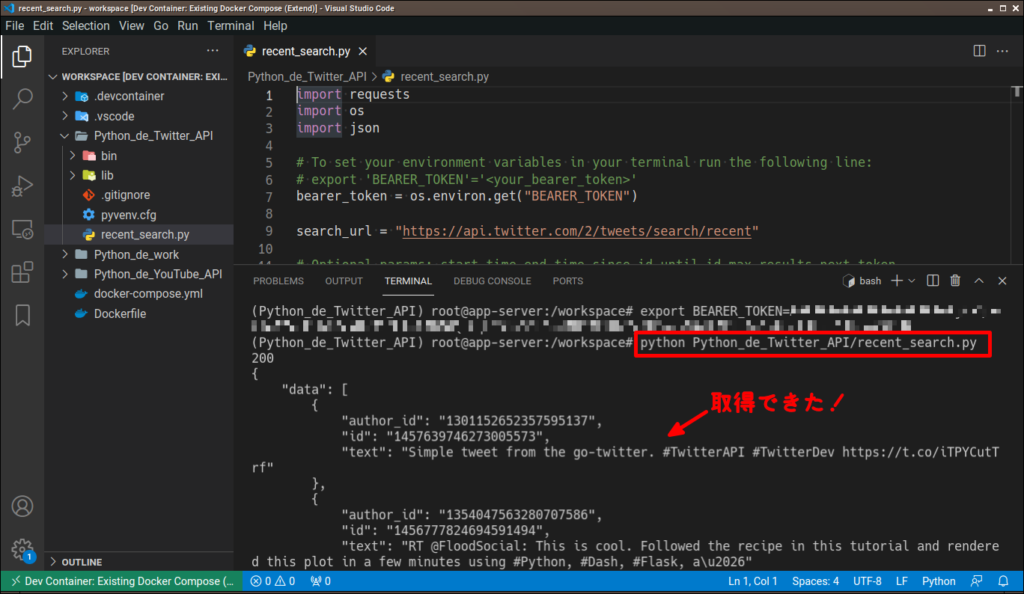
次は前記事と同様に、自分のツイートを取得してます。サンプルプログラムを少し修正するだけで簡単に取得できるようになります。修正するのは 2 箇所。
※ ちなみに ID(mxkLlrpl4qNvH5i)は別のものに変更したため、もう存在しません。
query_paramsに指定されている'query'の値を自分用に変更するjson.dump()時に日本語が変換されないようにensure_ascii=Falseを追加
※前パラメータとはカンマ+スペース「,」で繋げてください。
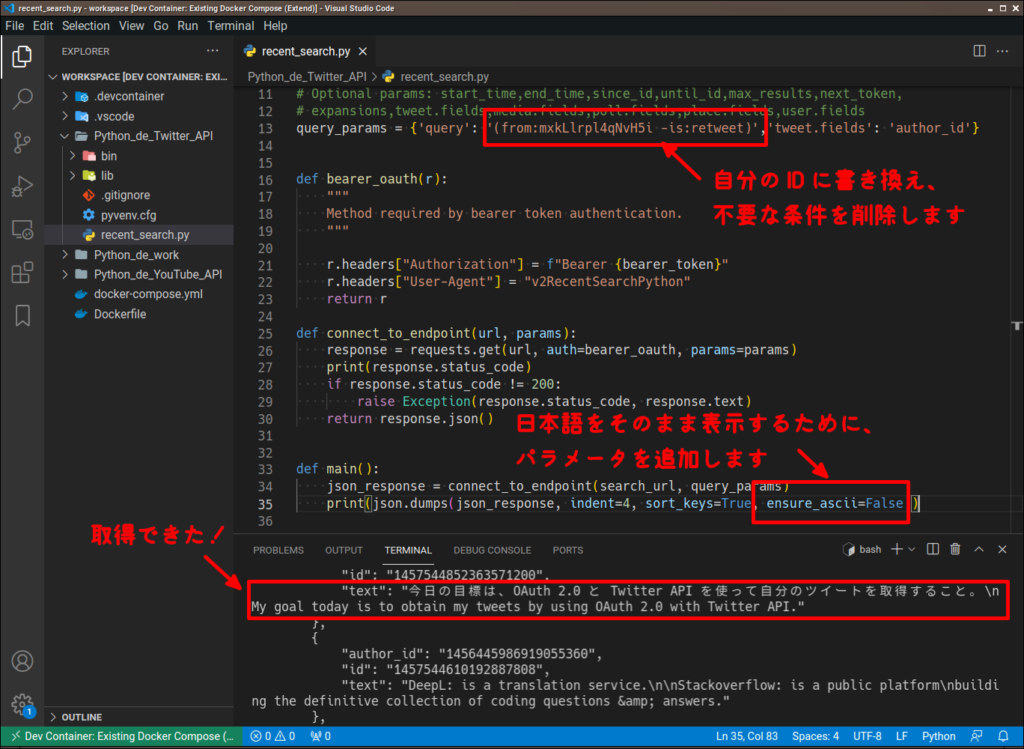
API とサンプルプログラムを使うと簡単ですね!
「さらに読み込む」的なやつにも挑戦!
「次のページへ」「さらに読み込む」的な機能は、”ページング(paging)” とか “ページネーション(pagination)” といいます。どちらも同じ意味で使えます。
Twitter API のドキュメント内では “ページネーション” が使われていますので、この記事内ではそちらを使用します。
今回使った Recent Search API では「max_results」パラメータを使って 1 回のリクエストで取得できる最大取得件数を指定できます。デフォルトが 10 件、パラメータで指定できるのは 10 〜 100 件となります。
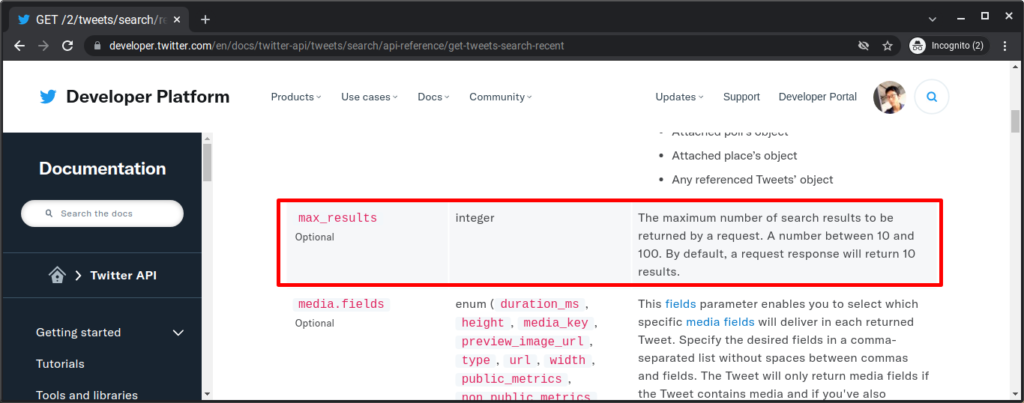
当然、それでは用を成さない人もいらっしゃると思いますので、ここではページネーションのやり方を確認しておきます。Twitter API でのページネーションは基本的に下記の流れになっています。
- 次、または前ページの情報がある場合は、それらを取得するためのトークン文字列が、取得した結果に含まれている
- 次、または前ページの情報を取得する場合は、結果に含まれていたトークンをリクエストのパラメータに含める
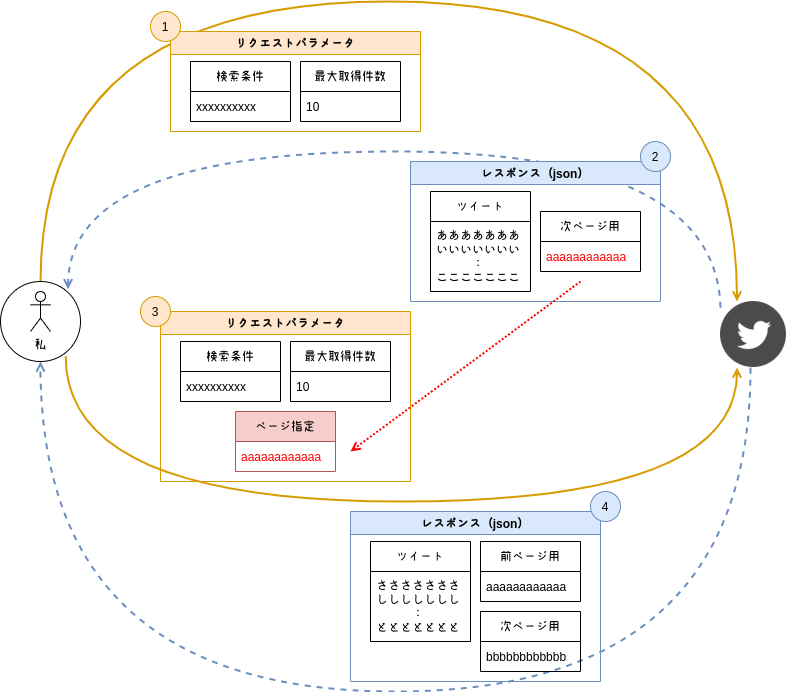
ただし!今回、確認に使う API「Recent Search」では以下の前提があります。仕様は API によって様々なので他の API を利用する前には確認するようお願いします。
- 最新のツイートから順番に取得
- “次へ” はあるけど、”前へ” はない
本投稿のために準備していたタイミングで私のツイートは全 11 件となります。10 件と 1 件に分けて取得できることを確認します。また Python を使うより curl コマンドを使用するほうが、逐次実行には向いておりますので、ここでは curl を使用して確認します。
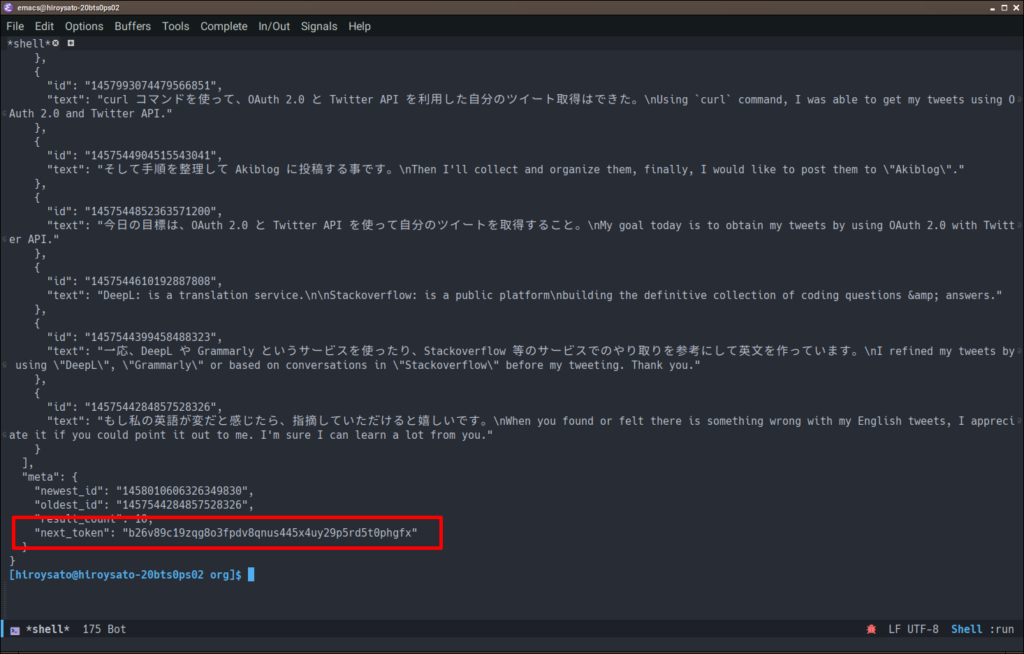
まずは先程と同じコマンドでツイートを 10 件取得します。すると「meta」というカテゴリの中に「next_token」という情報が含まれていることが確認できるはずです。
ここで取得した値を次のリクエストの「next_token」パラメータに指定すればページネーションの完成です!具体的には以下のコマンドになります。
curl -G \ "https://api.twitter.com/2/tweets/search/recent" \ --data-urlencode "query=from:mxkLlrpl4qNvH5i -is:retweet" \ --data-urlencode "max_results=10" \ --data-urlencode "next_token=b26v89c19zqg8o3fpdv8qnus445x4uy29p5rd5t0phgfx" \ -H "Authorization: Bearer $BEARER_TOKEN" \ | python -c 'from sys import stdin; import json; print(json.dumps(json.loads(stdin.readline()), indent=2, ensure_ascii=False))'
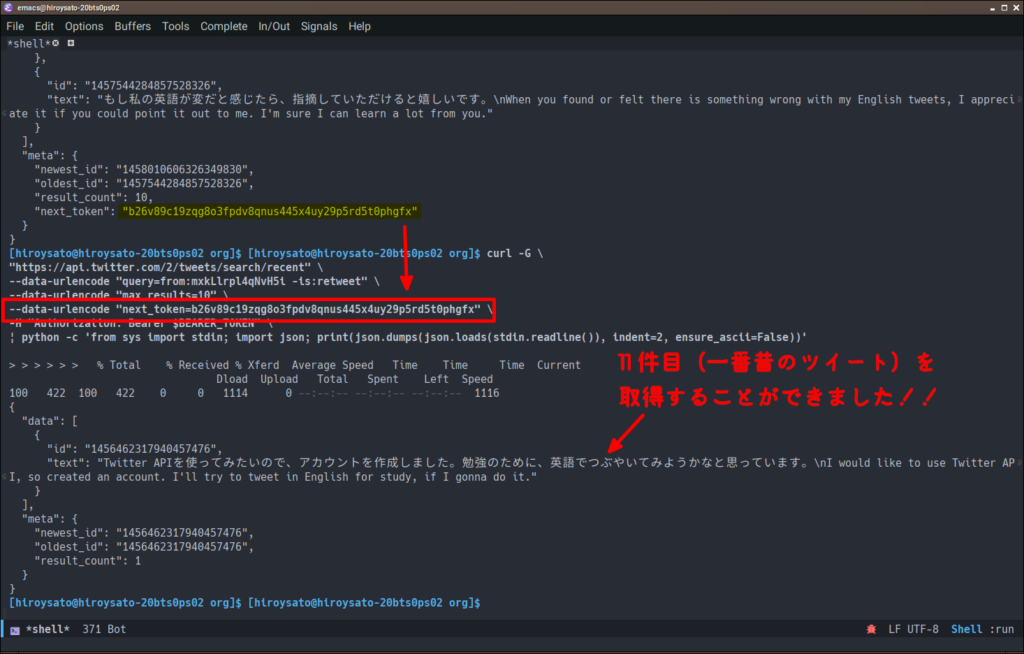
できました!
その他の基本的な仕様
API 関する基本的な仕様は、Twitter Developer Platform の Twitter API にある「Fundamentals」内にまとめられています。困ったらこちらを確認してみるといいかも知れません。
ちなみにページネーションに関する記事の中には以下の注意書きがありましたので、それだけ紹介して、今回の記事を終わりにします。
Pagination should not be used for polling purposes. To get the most recent results since a previous request, review polling with since_id.
(訳)
Pagination | Docs | Twitter Developer Platform
ページネーションは、ポーリング(※)の目的で使用してはいけません。前回のリクエスト以降の最新の結果を取得するには、since_idを使ったポーリングを確認してください。
※一定間隔でリクエストすること。ここでは、新しいツイートを確認するために定期的に API を利用することを指す
Twitter API のトップページは こちら 。

コメント