
現時点のスロットゲームでは、以下 4 つの問題点があります。
- 掛けコイン数に数字以外を入力するとエラーが発生する
- 掛けコイン数に負数を指定することができる
- 所持コイン数以上の掛けコイン数を指定することができる
- 所持コイン数が 0 枚にならないとゲームが終わらない
今回から数回に分けて上記 3 つの問題を解消するためにプログラムを修正していきましょう。今回は 1 つ目の問題点を解消します。
エラーになるパターンを知る
まずどのような場合にエラーになるのかを確認しておきましょう。画面に表示されるメッセージ等を頼りにプログラムの場所を特定します。
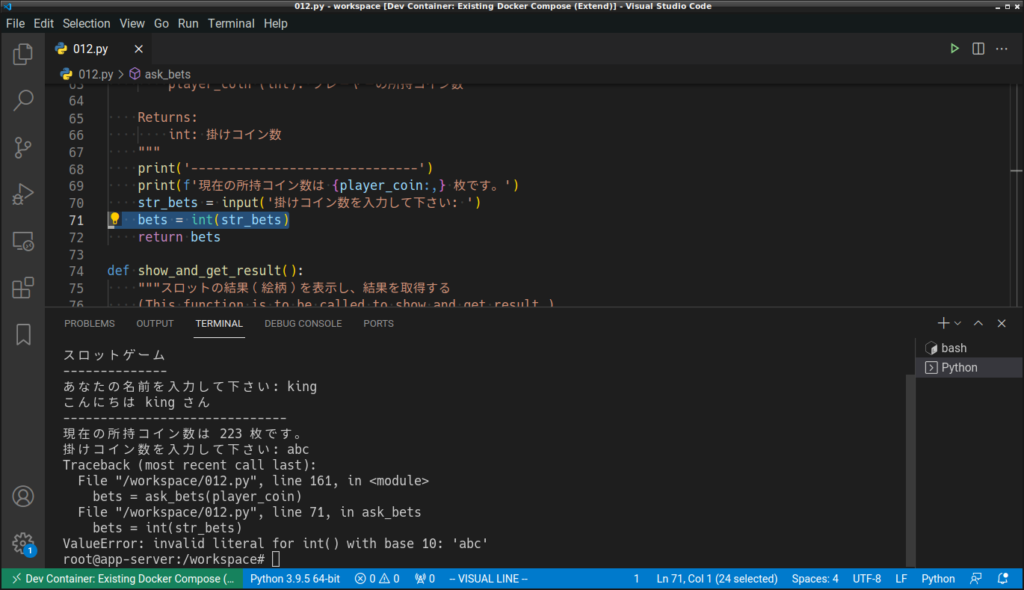
エラーになった際に表示され内容や、「int()」という文字列を整数に変換する関数が使われているという事実から、エラーが発生するのはこの「int()」を使用したタイミングであることが分かります。
では、掛コイン数でどのような値を指定した場合に実際にエラーになるのかを確認します。以下では唐突に「try〜except」の構文が登場します……これについては別途、記事を作成したいと思いますので、ここでは “エラーが起きてもプログラムが強制終了しない仕組み” という程度で捉えて下さい。
target_strings = [
'123', # 半角数字
'abc', # 半角英字
'+123', # + 付き
'-123', # - 付き
'3.14', # 小数点数
'456', # 全角数字
'四五六', # 漢数字
'ⅣⅤⅥ', # ローマ数字
'①②③', # 丸囲み文字
'¼⅕⅙', # 分数表記
'⑷𝟝५' # その他: U+2477、U+1D7DD、U+096B
]
for s in target_strings:
try:
i = int(s)
print(f"int('{s}') ==> {int(s)}")
except:
print(f"int('{s}') ==> Error!")
| 値 | 内容 | int() |
| ‘123’ | 半角数字 | 123 |
| ‘abc’ | 半角英字 | Error! |
| ‘+123’ | + 付き | 123 |
| ‘-123’ | - 付き | -123 |
| ‘3.14’ | 小数点数 | Error! |
| ‘456’ | 全角数字 | 456 |
| ‘四五六’ | 漢数字 | Error! |
| ‘ⅣⅤⅥ’ | ローマ数字 | Error! |
| ‘①②③’ | 丸囲み文字 | Error! |
| ‘¼⅕⅙’ | 分数表記 | Error! |
| ‘⑷𝟝५’ | その他 | Error! |
(「その他」には U+2477、U+1D7DD、U+096B を使用しました)
調査完了。
上記表中の数字表現は『Numerals | Unicode キャラクター図鑑』を参考にしました。
入力検証(バリデーション)
ユーザが入力した内容が、プログラムで使えるものかどうかを判断するための処理を “入力検証” や “バリデーション” といいます。現時点のプログラムでイケてないところは、入力された掛けコイン数に対して、全く入力検証(バリデーション)を行っていない点になります。入力後、それが正しいものかどうかを判断するためのロジックを追加しましょう。
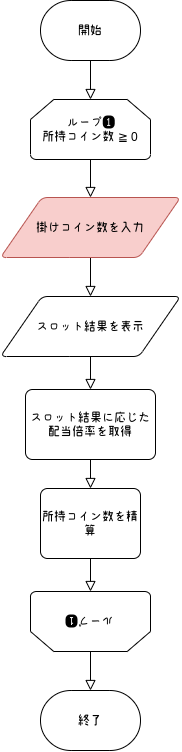
そんなに難しく考える必要はなく、「数字だけ?」「所持コイン数以下?」を確認すればいいので、フローチャートにするとこうなります。
(ちなみにこのフローチャートは draw.io という無料のサービスを使って描きました)
修正前
修正後
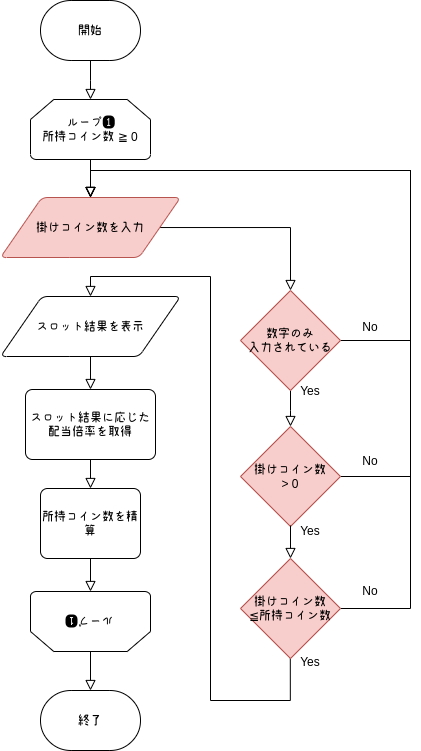
次の課題は各判定を、どのようにプログラムで記載するかになります。
「数字のみ」を判断する!
「input()」関数は、入力として任意の文字列を受け付けます。(そのため、関数の “戻り値” も文字列(string)型になります)
では、ユーザが入力した文字列が「数字のみ」であることを判定するにはどうしたらいいでしょうか?パッと思いつくところで方法は 2 つあります。一つは Python の文字列型に用意された関数を使用する方法。もう一つは “正規表現” を使って確認する方法。最後に、エラーが発生してもプログラムが終了しない仕組みを組み込む方法です。
- Python の文字列型に用意された関数を使用する方法
- “正規表現” を使って確認する方法
では、順番に確認していきます。
Python の文字列型に用意された関数を使用する方法
Python は、文字列型の値(またはそれが代入された変数)に対して「それは数字ですか?」と問いかける関数が用意されています。使い方はとっても簡単で「.isdigit()」をくっつけるだけです。これで Python は「はい(True)」または「いいえ(False)」を返してくれます。
Python には他にも「数を表す文字?→.isnumeric()」や、「文字が十進数字?→.isdecimal()」があります。簡単な使い方と、それぞれの違いを確認しましょう。
詳細は『文字列メソッド | 組み込み型 – Python 3.9.4 ドキュメント』を参照して下さい。こちらには、他にも「文字が英数字→.isalnum()」等、色々な関数が載っています。便利な関数はないかな?と確認してみるのもいいと思います。
target_strings = [
'123', # 半角数字
'abc', # 半角英字
'+123', # + 付き
'-123', # - 付き
'3.14', # 小数点数
'456', # 全角数字
'四五六', # 漢数字
'ⅣⅤⅥ', # ローマ数字
'①②③', # 丸囲み文字
'¼⅕⅙', # 分数表記
'⑷𝟝५' # その他: U+2477、U+1D7DD、U+096B
]
for s in target_strings:
print(s)
print(f'.isdigit() ==> {s.isdigit()}')
print(f'.isnumeric() ==> {s.isnumeric()}')
print(f'.isdecimal() ==> {s.isdecimal()}')
| 値 | 内容 | isdigit() | isnumeric() | isdecimal() |
| ‘123’ | 半角数字 | True | True | True |
| ‘abc’ | 半角英字 | False | False | False |
| ‘+123’ | + 付き | False | False | False |
| ‘-123’ | - 付き | False | False | False |
| ‘3.14’ | 小数点数 | False | False | False |
| ‘456’ | 全角数字 | True | True | True |
| ‘四五六’ | 漢数字 | False | True | False |
| ‘ⅣⅤⅥ’ | ローマ数字 | False | True | False |
| ‘①②③’ | 丸囲み文字 | True | True | False |
| ‘¼⅕⅙’ | 分数表記 | False | True | False |
| ‘⑷𝟝५’ | その他 | True | True | False |
(「その他」には U+2477、U+1D7DD、U+096B を使用しました)
使えそうなのは「isdecimal()」のようです。
“正規表現” を使って確認する方法
正規表現(せいきひょうげん、英: regular expression)は、文字列の集合を一つの文字列で表現する方法の一つである。
(略)
ほとんどのプログラミング言語では、ライブラリによって正規表現を使うことができる
正規表現 – ウィキペディア
つまり
- 日本の携帯電話番号は「数字3文字-数字4文字-数字4文字」で構成されています
- 名前に使える漢字は「人名用漢字と常用漢字のみ」です
という表現方法ができますよ、と言う事になります。
今回の主題である「数字のみ」については「^[0-9]+$」や「^\d+$」で、それぞれの記号は
^:文字列の先頭[0-9]:0〜9 の間の文字\d:数字+:1文字以上$:文字列の末尾
を意味していますので、「先頭から末尾まで 0〜9 で 1 文字以上」、「先頭から末尾まで数字で 1 文字以上」という表現をしています。
その他の有意義な情報を含め、より詳細な情報は『正規表現のシンタックス | re — 正規表現操作』を参照下さい。
ところで Python で “正規表現” を使用するためには、「re」(regular expression)モジュールをメモリ上に読み込む必要があります。PC のメモリを “作業机” に例えることがよくありますが、ここでも同様のイメージを持ってください。Python がプログラムを実行している作業机に、正規表現用の道具を持ってくるイメージです。
Python の正規表現の関数「search()」は
import re
target_strings = [
'123', # 半角数字
'abc', # 半角英字
'+123', # + 付き
'-123', # - 付き
'3.14', # 小数点数
'456', # 全角数字
'四五六', # 漢数字
'ⅣⅤⅥ', # ローマ数字
'①②③', # 丸囲み文字
'¼⅕⅙', # 分数表記
'⑷𝟝५' # その他: U+2477、U+1D7DD、U+096B
]
patterns = [
r'^[0-9]+$',
r'^\d+$'
]
for p in patterns: # 各パターン毎にループを回す
for s in target_strings: # 対象の文字列を一つずつ確認する
print(f"'{p}' search '{s}'.: ", end='') # (裏ワザ)「end=''」とすると改行しなくなる
if re.search(p, s):
print('Found!')
else:
print('Not found.')
| 値 | 内容 | r'^[0-9]+$' | r'^\d+$' |
| ‘123’ | 半角数字 | Found! | Found! |
| ‘abc’ | 半角英字 | Not found. | Not found. |
| ‘+123’ | + 付き | Not found. | Not found. |
| ‘-123’ | - 付き | Not found. | Not found. |
| ‘3.14’ | 小数点数 | Not found. | Not found. |
| ‘456’ | 全角数字 | Not found. | Found! |
| ‘四五六’ | 漢数字 | Not found. | Not found. |
| ‘ⅣⅤⅥ’ | ローマ数字 | Not found. | Not found. |
| ‘①②③’ | 丸囲み文字 | Not found. | Not found. |
| ‘¼⅕⅙’ | 分数表記 | Not found. | Not found. |
| ‘⑷𝟝५’ | その他 | Not found. | Not found. |
(「その他」には U+2477、U+1D7DD、U+096B を使用しました)
「\d」を使った方は上記「isdecimal()」と同じ結果になりました。
お気づきの方もいらっしゃるかと思いますが、正規表現の文字列の前に「r」がついています。これは raw 文字列記法 という表記です。捜査対象の文字列が、Windows のファイルのパスの様にバックスラッシュ「\」が含まれる場合に役に立ちます。
バックスラッシュ「\」は、その他の文字と組み合わせて「\n → 改行」や「\t → タブ」等を表現したり「'I\'m hungry.'」の様に文字列中のクォートをエスケープしたりするのに使用します。そのため、Windows のファイルパスを表現する時はバックスラッシュ自体をエスケープする必要があり、結果「C:\\Users\\hiroysato\\Desktop」の様に書く必要が出てきます。これを正規表現で捜査するには「C:\\\\Users\\\\hiroysato\\\\Desktop」とする必要があり、見づらく間違いもおかしやすい状態です。raw 文字列記法はそれを解消するための書き方になります。
import re
re.search('C:\\Users', 'C:\\Users\\hiroysato') #==> re.error: incomplete escape \U at position 2
re.search('C:\\\\Users', 'C:\\Users\\hiroysato') #==> <re.Match object;...> ※マッチオブジェクトを取得
# raw 文字列記法を使うとバックスラッシュをエスケースしなくていい
re.search(r'C:\\Users', 'C:\\Users\\hiroysato') #==> <re.Match object;...> ※マッチオブジェクトを取得
Python で正規表現を使う際には raw 文字列記法もセットで使うようにしておくと良いでしょう。
パターンを表現するのに raw 文字列を使っていないのであれば、 Python もまた、バックスラッシュを文字列リテラルでエスケープシーケンスとして使うことを思い出して下さい。そのエスケープシーケンスを Python のパーザが認識しないなら、そのバックスラッシュとそれに続く文字が結果の文字列に含まれます。しかし、Python が結果のシーケンスを認識するなら、そのバックスラッシュは 2 回繰り返さなければいけません。これは複雑で理解しにくいので、ごく単純な表現以外は、全て raw 文字列を使うことを強く推奨します。
正規表現のシンタックス | re — 正規表現操作
プログラムをやる上で、”正規表現” は避けては通れません!……というか便利なので仕事でもよく使います。慣れておいて絶対に損はないです!でも、奥が深い!!
search() vs. match()
ちなみに「search()」とよく似た関数に「match()」があります。この違いについては Python の公式ドキュメントで以下のように説明されているとおりです。正規表現といえば Perl というプログラミング言語が老舗なため、他のプログラミング言語、ライブラリも Perl を参考に作られていることが多いです。そのため今回は Perl のデフォルトの挙動と同じ「search()」を使うようにしています。
Python は正規表現ベースの 2 つの異なる基本的な関数、文字列の先頭でのみのマッチを確認する
search() vs. match() | re — 正規表現操作re.match()および、文字列中の位置にかかわらずマッチを確認するre.search()(これが Perl でのデフォルトの挙動です) を提供しています。
エラーが発生してもプログラムが終了しない仕組みを組み込む方法
入力検証(バリデーション)を組み込むことで、エラーが発生するのを事前に防ぐ方法について確認してきました。しかし本項タイトルにもあるように、エラーが発生してもプログラムが終了しない仕組みを組み込むことも可能です。
これは以下 2 つを使って実現できます。「try〜except」については上記同様、今は簡単に “エラーが発生してもプログラムが終了しない仕組み” 程度で捉えて下さい。
while True:を用いた無限ループtry〜exceptを用いて、エラーが発生してもプログラムが終了しないようにする
def validation_test():
while True:
try:
str_bets = input('掛けコイン数を入力して下さい: ')
return int(str_bets)
except:
continue
bets = validation_test()
print(bets)
結論
何となく最後の「エラーが発生しても〜」の仕組みが最強なような気がするかも知れません。実際に一番、安全な方法だと思います。しかし、この仕組みは PC に高い負荷を与えますので “最終手段” と考え極力、別の方法を採用するのが望ましいです。
すると「456」(全角数字)を許可するか否か、、、が焦点になります。「int()」関数では全角数字を正しく変換できるので、ユーザー入力として受け付けてもよいのです。しかし、プログラムの世界では全角/半角を厳しく区別するのが一般的かと思いますので、今回は半角数字のみを許可する “正規表現” による入力検証(バリデーション)を採用したいと思います。
次回、実際にプログラムを修正いたします。

コメント